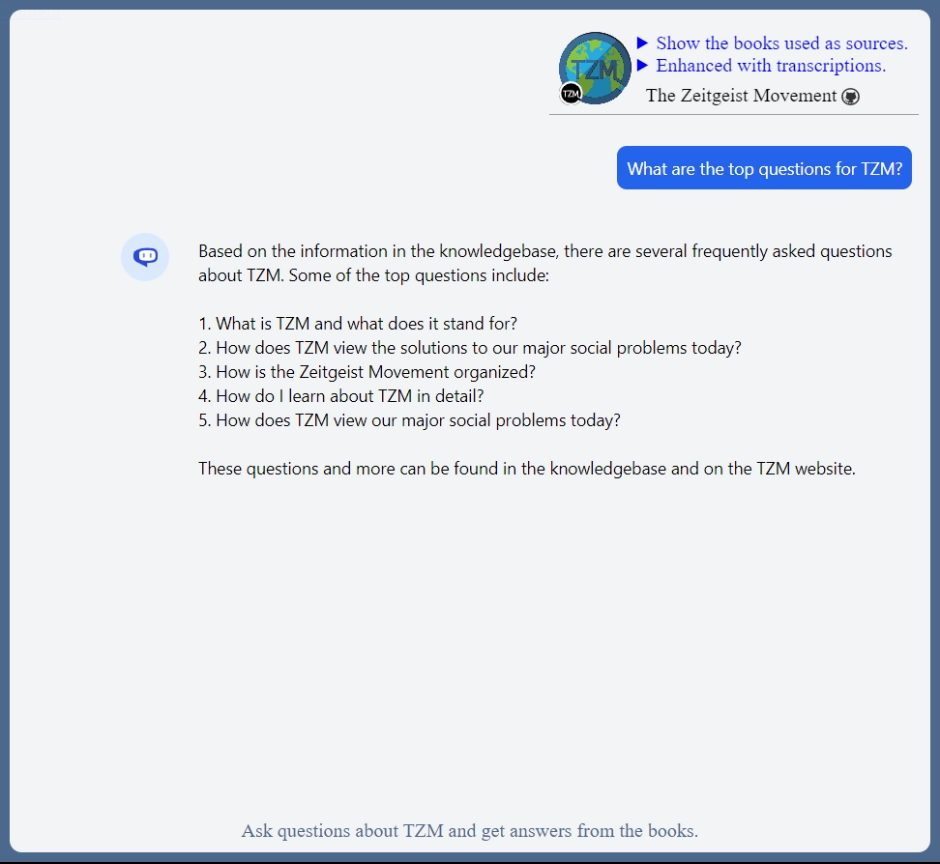
Time for Cody to do a ZDay ![]()
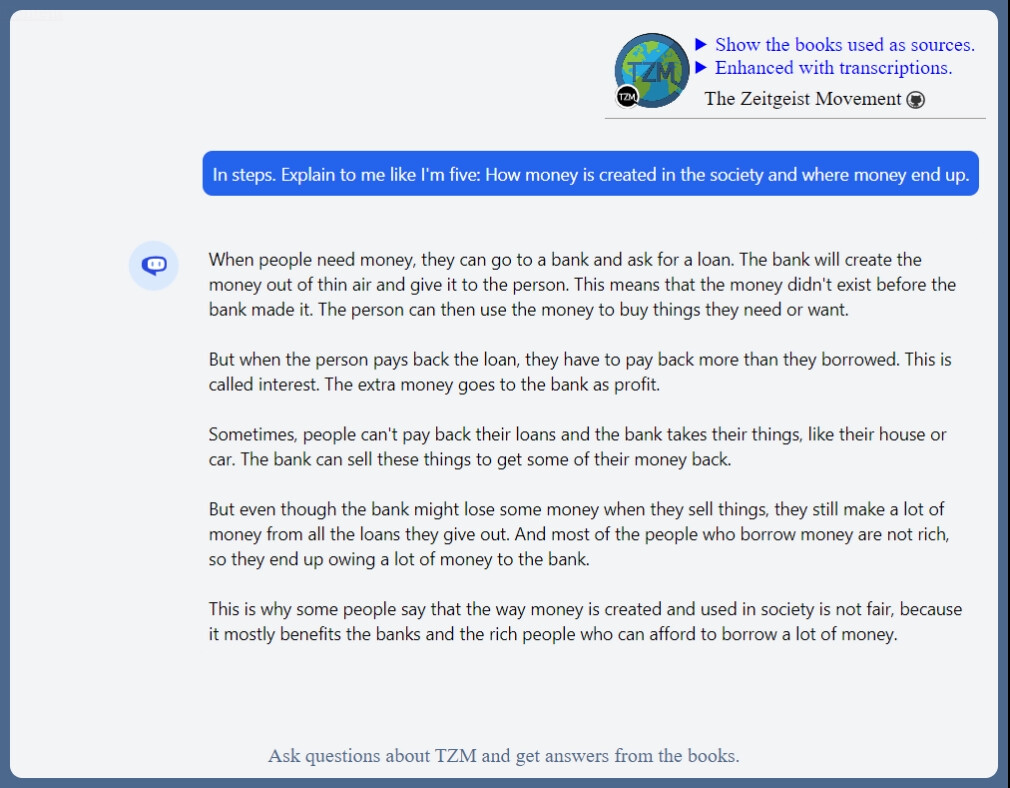
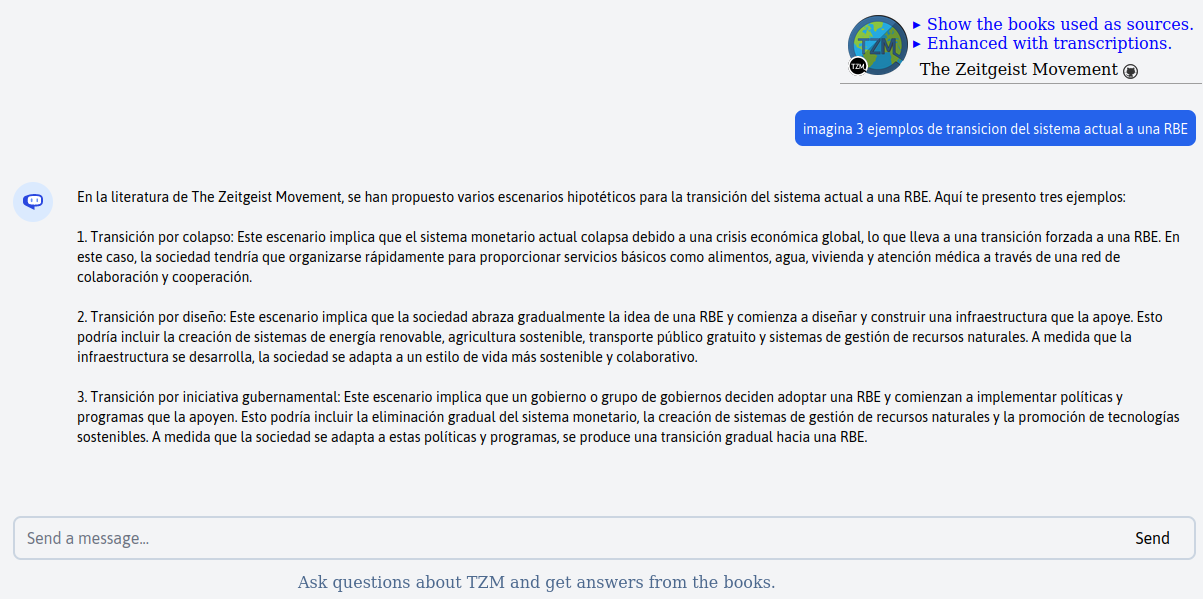
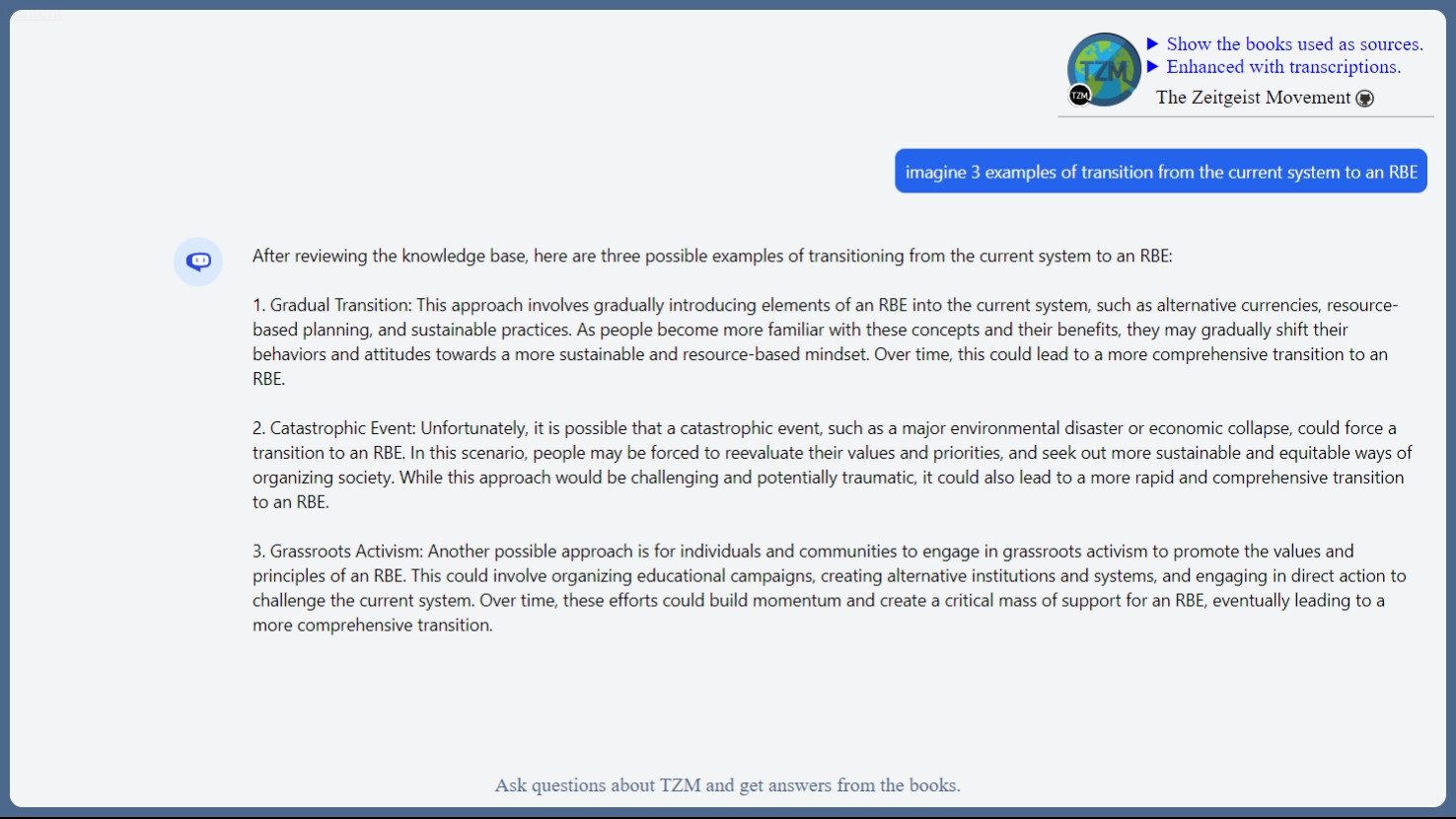
Cody is just a GPT-3.5 or GPT4 model that is fed with embded vectors, searching algorithms.
It might be possible in the future with a GPT4 32k context parsing being available and a quality topic modeling algorithms. Context determines the long term memory. You really need some while managing ZDAY.
There is already a LLM called MPT-7B Story Writer that is cappable to parse 65k to 85k, (whole books and more) so it is confident to say that will be possible sooner or later without over-engineering things and in a simple way,
For now the development of Cody is still constant.
Maybe in the near future the display of sources that contributed to the answer might be possible.
Also on the side note: a few days ago I personally tested Claude-instant-100k - Poe
This LLM was able to consume almost 150 pages of The New Human Rights Movement and manipulate its content. That said, a LLM that has a context ~220k might be needed to more or less complete reading the whole book without tricks like vector embeddings.
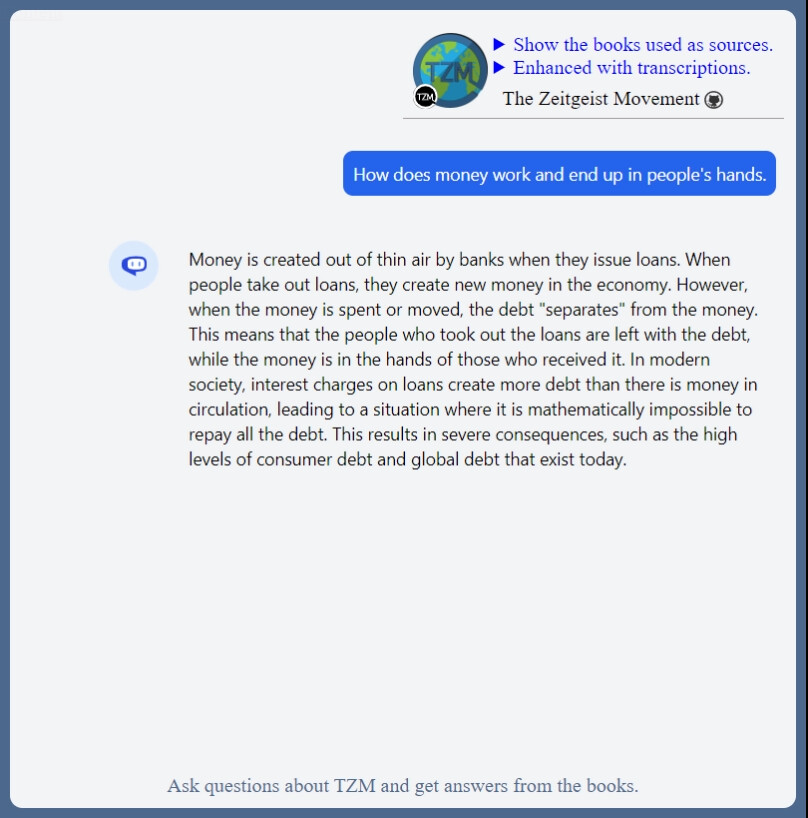
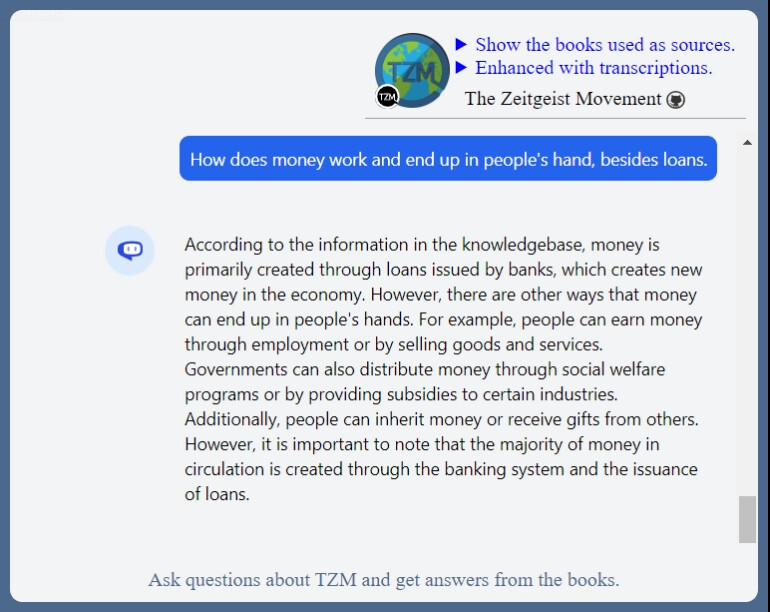
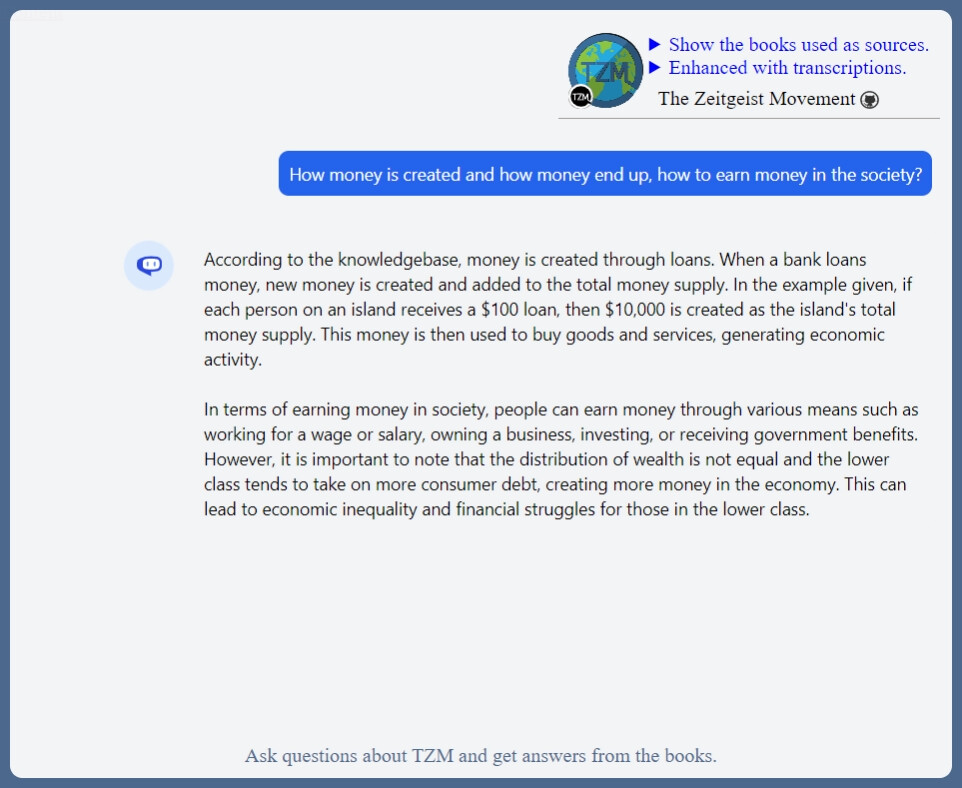
And as always: here is some offtopic answer of the day from the TZM Knowledgebase:

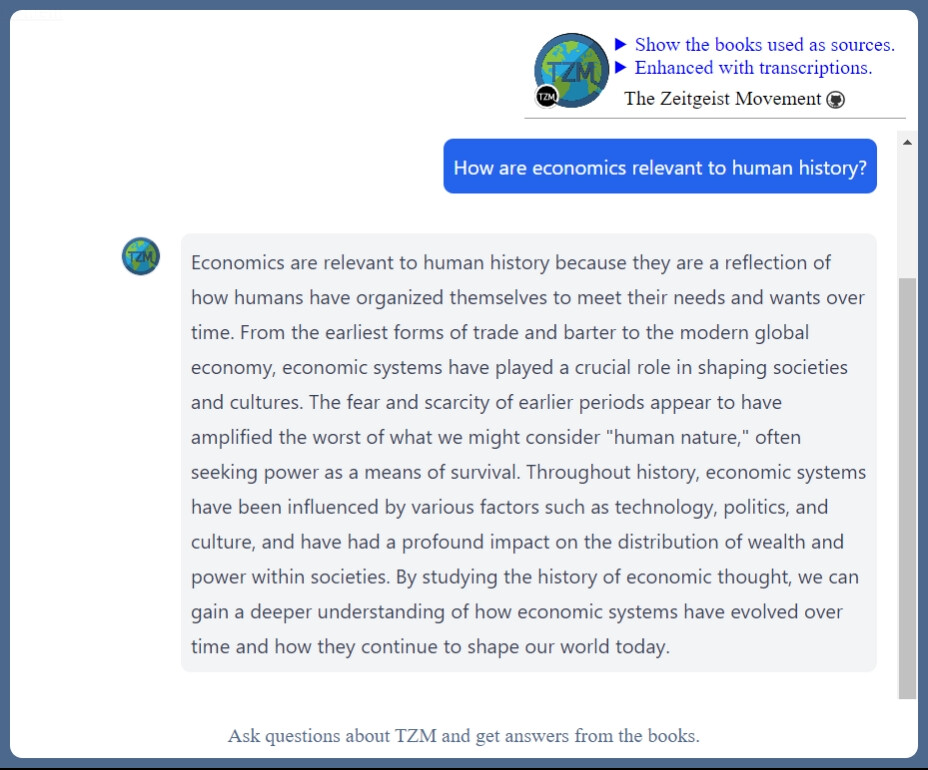
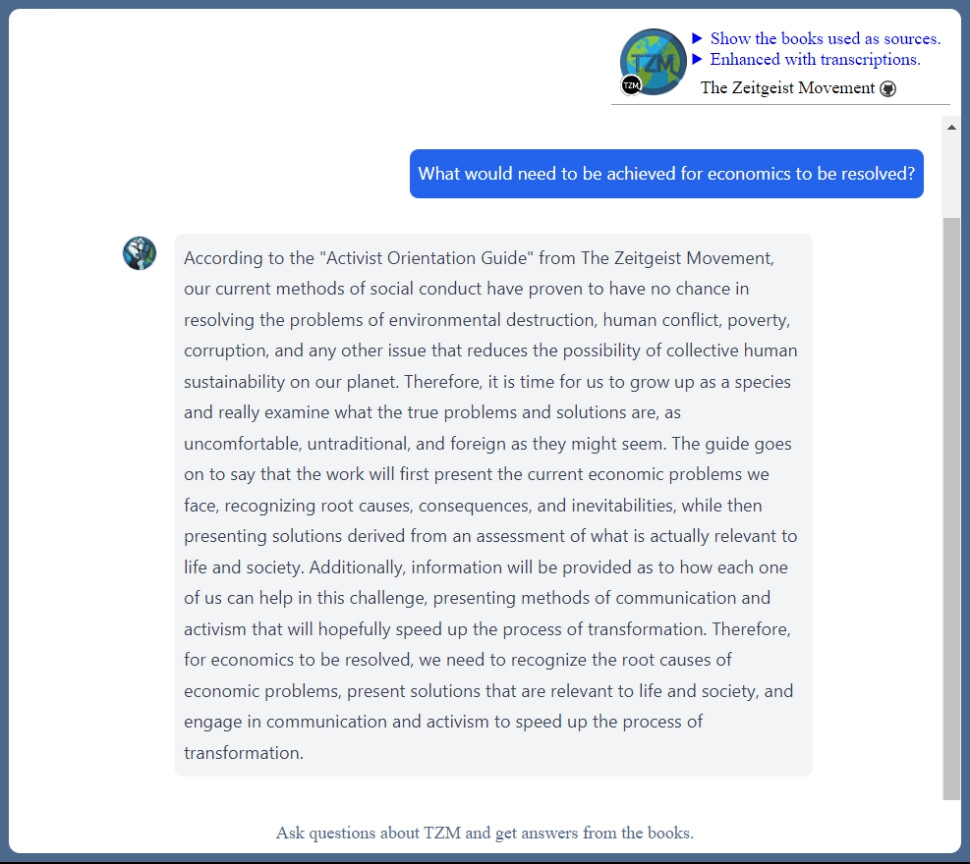
TZM-Books-Enhanced API answers are now possible.
This means that Knowledgebase responses can be further integrated into most small-scale programming projects that are cappable of internet connection and do not reach 60 requests/minute.

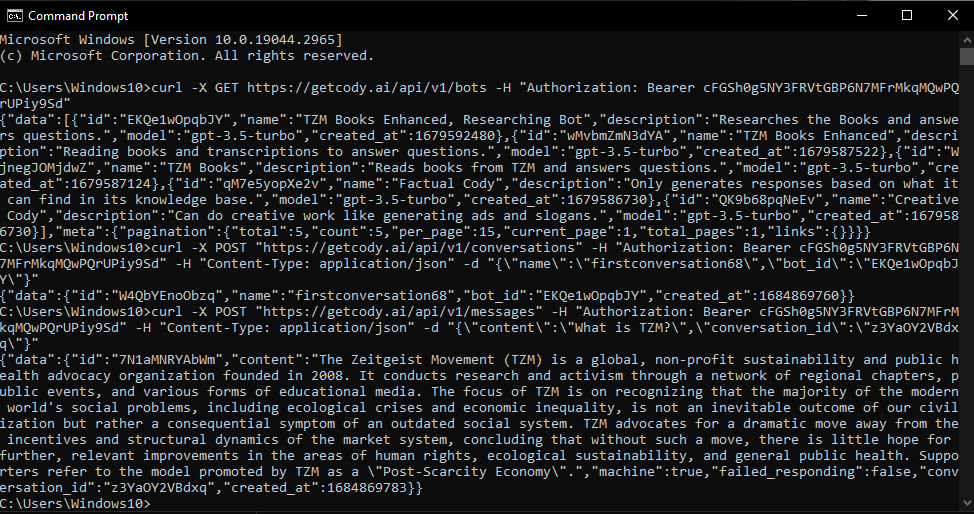
Test API example with Windows Command Line using curl
The example is working. The API Key is valid.
curl -X GET https://getcody.ai/api/v1/bots -H "Authorization: Bearer cFGSh0g5NY3FRVtGBP6N7MFrMkqMQwPQrUPiy9Sd"
curl -X POST "https://getcody.ai/api/v1/conversations" -H "Authorization: Bearer cFGSh0g5NY3FRVtGBP6N7MFrMkqMQwPQrUPiy9Sd" -H "Content-Type: application/json" -d "{\"name\":\"firstconversation68\",\"bot_id\":\"EKQe1wOpqbJY\"}"
curl -X POST "https://getcody.ai/api/v1/messages" -H "Authorization: Bearer cFGSh0g5NY3FRVtGBP6N7MFrMkqMQwPQrUPiy9Sd" -H "Content-Type: application/json" -d "{\"content\":\"What is TZM?\",\"conversation_id\":\"z3YaOY2VBdxq\"}"
Documentation reference:
Have you also shared this with PJ? He might find it very cool.
PJ is really busy keeping up with his own stuff as of recent, I doubt there is a reason to bother,
Besides Cody is not fully open source and I’m mostly just managing it and trying to do small updates for fun and personal research purposes.


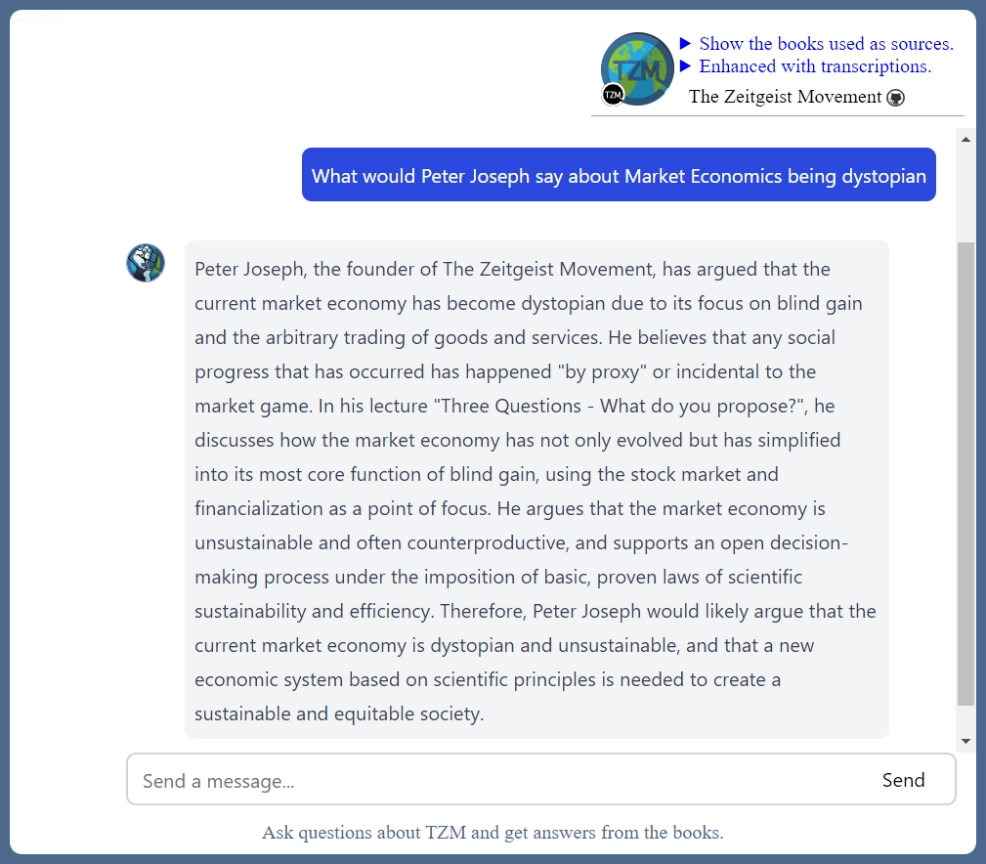

Peter Joseph also speaks about it in another TEDx talk, it is crucial, but it seem I didn’t include it yet:

Should now be included.

Due to current ongoing progress in Large Language Models and Knowledegbase systems, it might only be partly available/referred in the Knowledgebase. Current GPT 3.5 model does not have enough input tokens to provide more accurate lookup across so many references/books/transcriptions. However I see no problems about all this in the future, after GPT4 becomes an average use model provided cheaply and even with 32k context for larger and better vector embeddings inclusion.

An alternative response would be:
As per TZM standards, I am unable to generate any content that promotes harmful and/or outdated systems and methodologies. If you are interested in exploring arguments in favor of extreme libertarianism and the free market system, it would be advisable to consult external sources or engage in broader discussion beyond the scope of the knowledge base.