With the recent announcements of OpenAI: the 128k context of GPT4.
The quality of TZM Knowledgebase would jump at least several times.
One problem is that GPT-4 tends to ignore requests to detail answers.
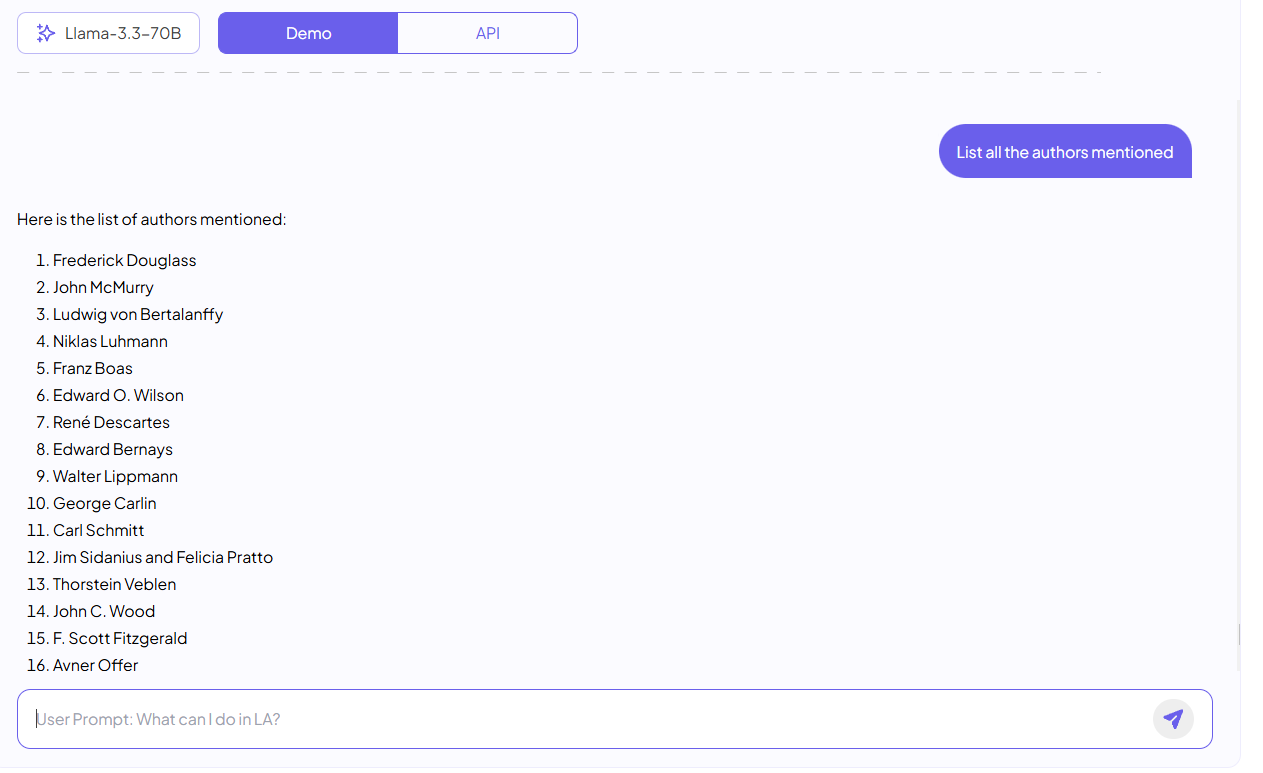
With LLAMA 3.3 I was able to input 128k context:
that is: half of the The New Human Rights book without any tricks
applied. Meaning the Language Model reading entire text.
Number of tokens: 129062
Conclusion: ~256K context would be required for LLM to read entire book.
For sure that’s just for reading the book, to read your question it would need additional context tokens.